sfi-hbase:一种基于二分混合空间填充曲线的hbase多维索引
sfi-九游会j9登录
hbase是一款流行的开源分布式数据库,能够支持海量数据的实时读写。然而,hbase并没有提供对多维索引的支持。针对这一问题,本文从线性化方法入手,使用z曲线等支持二分划分的空间填充曲线混合理论性质优良的其他空间填充曲线,提出一种新的二分混合空间填充曲线,不仅能够支持二分划分裁剪多维数据空间,并且拥有更好的局部性、聚集度。在实验条件下,使用z曲线混合hilbert曲线的blend_z_hilbert曲线在局部性指标上较z曲线提升20%以上,在聚集度指标上提升50%以上。接着,基于二分混合空间填充曲线降维后的一维数据,提出了一种基于流式批处理计算的hbase多维索引结构sfi-hbase。在数据插入方面,sfi-hbase使用spark streaming对插入全量索引层的数据提前进行聚合、存储,提供了对并发插入的支持,实现了良好的插入效率。在数据查询方面,sfi-hbase能够根据查询条件灵活选择索引粒度,实现快速的数据查询。最后,与多种hbase多维索引九游会j9登录的解决方案进行了插入和查询实验对比,结果表明本文提出的索引结构具有综合最优的时空效率。与线性化技术经典九游会j9登录的解决方案md-hbase相比,sfi-hbase的范围查询效率提高10%左右,knn查询效率提高5倍以上,插入效率提高十倍以上。
关键词:hbase,二分混合空间填充曲线,多维索引,流式计算
目录
摘要
1 介绍
2 动机
3 基于可变阶数的二分混合空间填充曲线
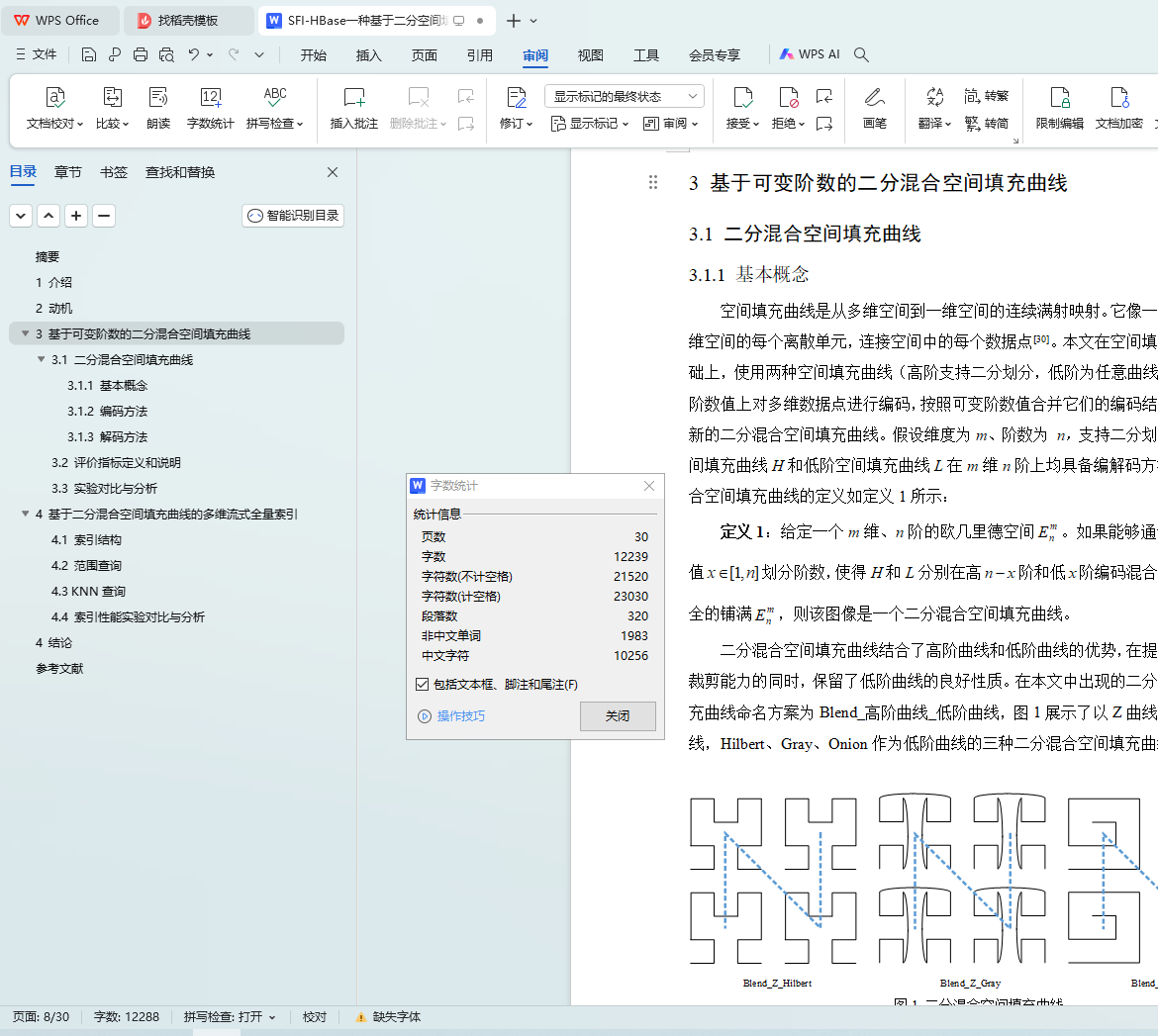
3.1 二分混合空间填充曲线
3.1.1 基本概念
3.1.2 编码方法
3.1.3 解码方法
3.2 评价指标定义和说明
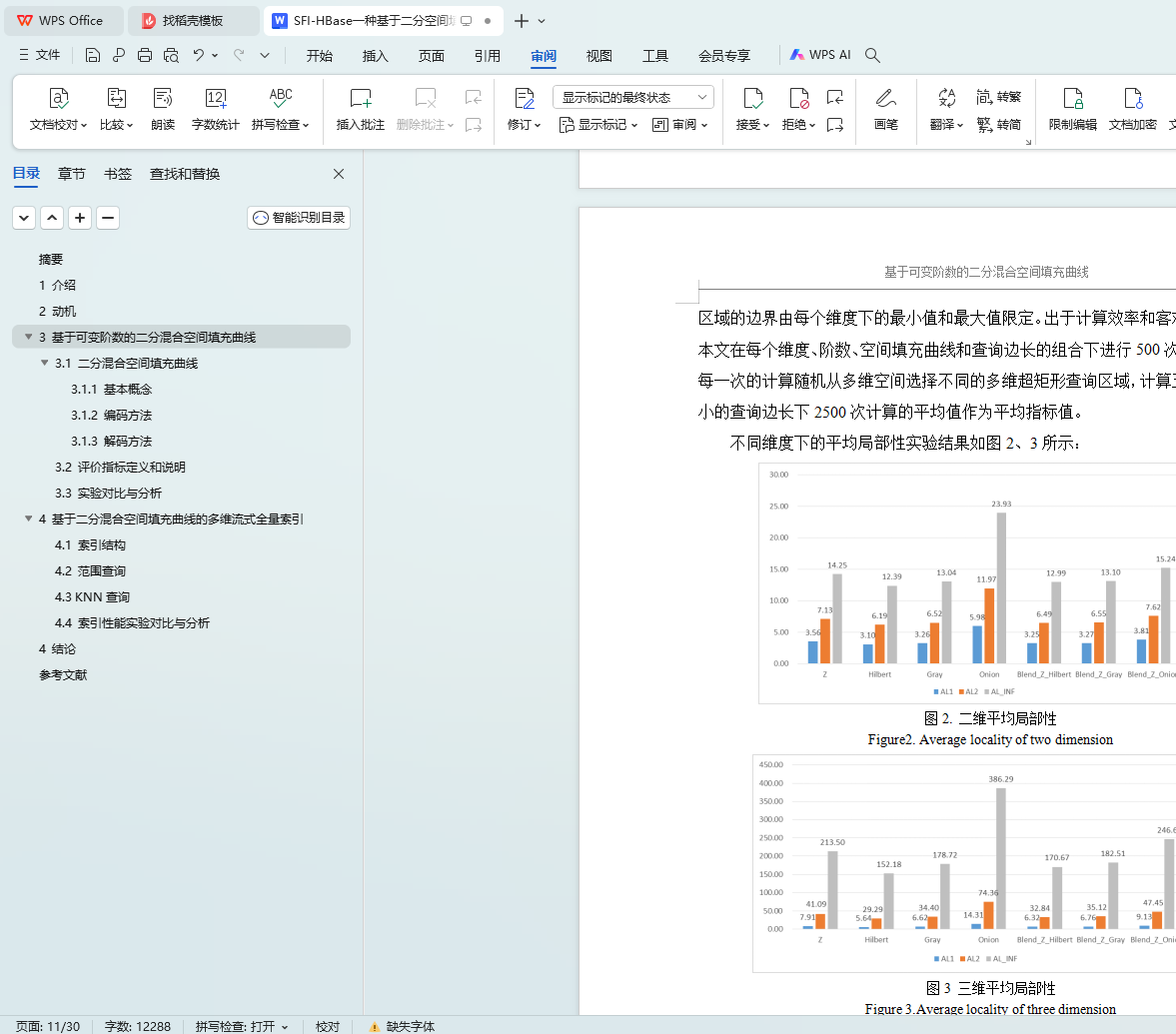
3.3 实验对比与分析
4 基于二分混合空间填充曲线的多维流式全量索引
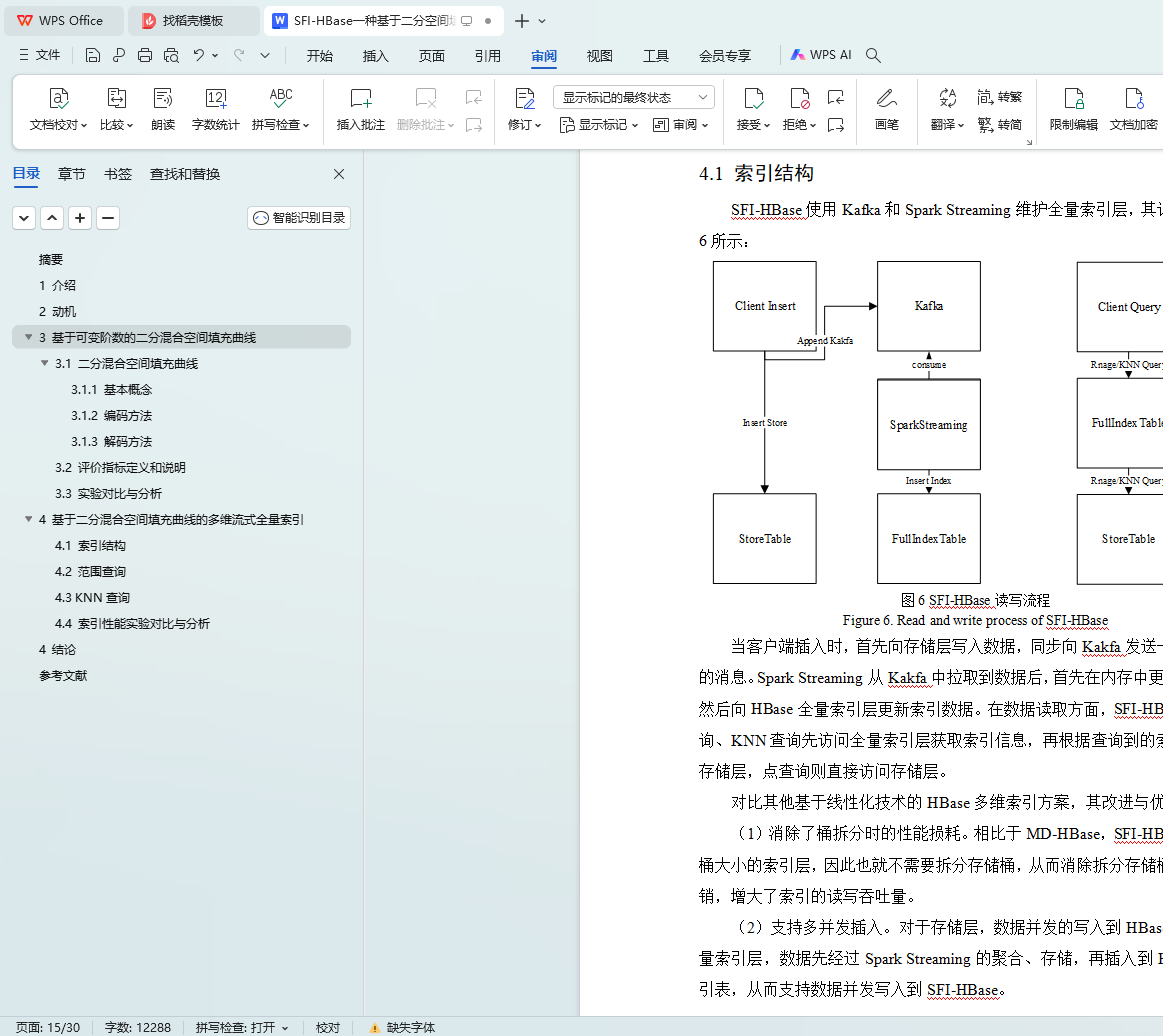
4.1 索引结构
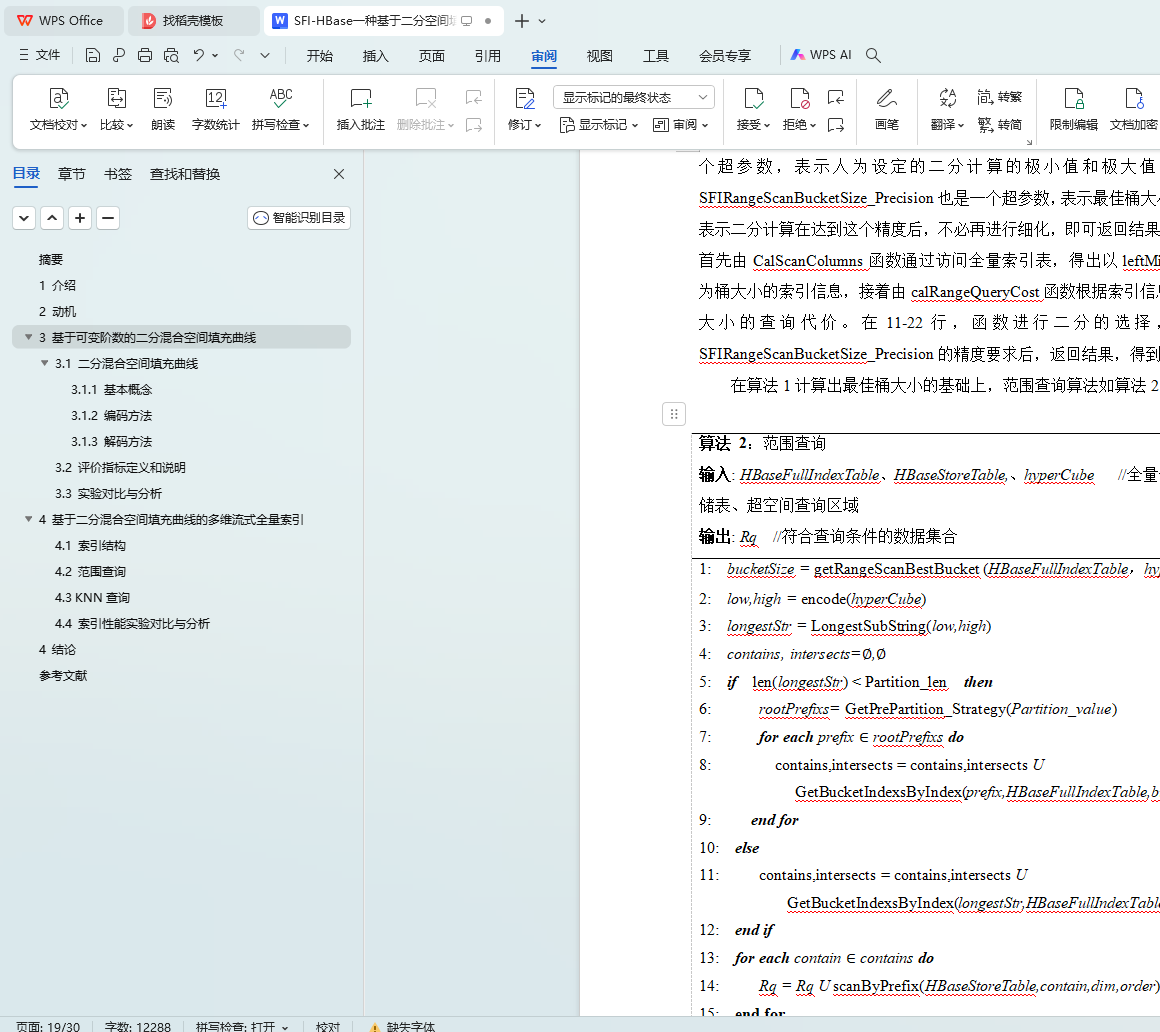
4.2 范围查询
4.3 knn查询
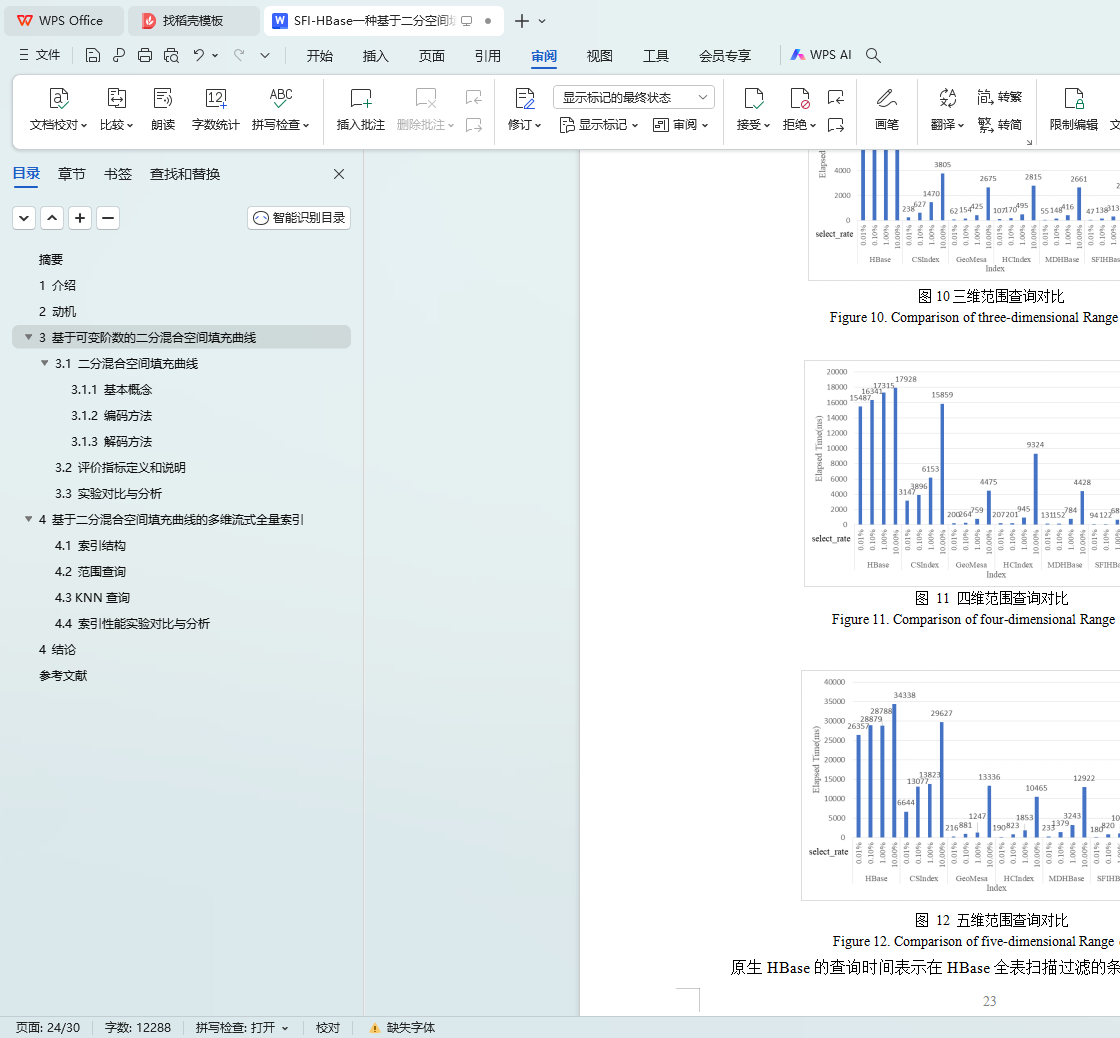
4.4 索引性能实验对比与分析
4 结论
参考文献
1 介绍
随着互联网用户规模的日益增长,产生了庞大的数据量。seagate和idc联合研究表明,到2025年全球数据量将达到163zb。海量的数据蕴含着巨大的价值和潜力,能够帮助企业制定正确的战略选择。然而,巨大的数据量也带来了数据存储和处理上的挑战。传统的关系型数据库由于在数据模型、拓展性和并发性能等方面的固有限制,无法处理如此大的数据量。因此,人们提出了一种新的数据库设计,即非关系型数据库nosql。
hbase是一个开源、分布式、多维和nosql数据库[1],在分布式文件系统hadoop之上提供了结构化/非结构化数据的快速随机读写,它具有一次性存储和处理十亿行数据的能力[2]。hbase底层采用lsm树作为存储结构,能够基于主键快速定位数据。然而,对于非主键的多维查询,hbase采用扫描全表数据并过滤的方法执行查询,查询效率低下。为了弥补这一缺陷,常见的做法是在原始数据表的基础上设计索引结构,并基于不同的方法对索引进行存储与管理。有研究[3]将索引方案分为以下三种:(1)二级索引方案(2)双层索引方案(3)基于线性化技术的全局索引方案。
二级索引方案根据存储位置的不同可以分为基于hbase自身存储的二级索引方案和基于第三方独立引擎的二级索引方案。基于hbase自身存储的二级索引:ithbase[4]和ihbase[5]出现在hbase早期版本的分支中,从源代码级别进行了扩展,在hbase的基础上支持了事务和索引,能够根据主表的数据变动同步更新索引表。然而,这两种九游会j9登录的解决方案都需要重构hbase,且不再继续更新。ccindex[6]为每个索引列保存了一张辅助索引表,以多副本机制保存数据。在根据单个索引列查询时,ccindex可以在对应的索引表中直接顺序扫描获得结果。然而,对于多个索引列的查询,ccindex查询所需的时间开销急剧增长,且该方案会占用较多的存储空间。hibase[7]是一种基于内存和磁盘的分层二级索引方案,它在磁盘上建立了基于主表的全局二级索引表,在内存上基于热度累积的缓存策略建立了缓存层的二级索引表。然而,hibase仅支持为一维数据建立索引,无法满足多维数据的查询情形。csindex[8]基于hbase的meta表和reigon分别建立了全局索引层和局部索引层,使用协处理器同步二级索引,获得了优秀的查询性能。然而,csindex对内存占用较大,且主要针对时空数据,不具备一定的通用性。
基于第三方独立引擎的二级索引方案:elasticsearch[9]是一个开源的全文搜索引擎,通过倒排索引提供强大的搜索能力。许多研究[10-12]使用elasticsearch在hbase上实现了二级索引,在执行查询时首先从elasticsearch中查询出主键集合,然后再返回hbase中根据主键执行查询。然而,在大数据量下,多维索引的查询去重可能会引起大量的时间消耗,且数据一致性的实时性难以保证。
双层索引可根据结构的不同分为两种:p2p结构的双层索引和集中式结构的双层索引。文献[13-15]使用p2p结构实现双层索引,支持动态的增加或者减少节点,使系统能够支持大规模的数据查询。然而,p2p网络的数据传输往往代价较高,会消耗大量的计算、网络资源。文献[16,17]使用集中式结构存储全局索引,在每个节点建立k-d树结构的局部索引,在单个节点上建立r树结构的全局索引,对局部索引节点进行索引。然而,随着维度和数据量的增大,r树各个节点之间的重叠部分会增大,从而在查询时会产生大量的误判结果。
基于线性化技术的全局索引方案首先通过线性化技术将多维数据映射为一维序列,然后在一维序列上构建高效的空间树索引,从而实现对多维数据的快速查询。md-hbase[18]使用z曲线将多维数据映射为一维数据,然后使用k-d树或者四叉树构建索引。然而由于hbase不支持事务特性,导致md-hbase无法支持数据的并发写入。且md-hbase索引层采用的z曲线理论性质较差,不利于底层数据的存储和查询。han等人结合四叉树和规则网格划分,设计了 hgrid[19] 结构,有效的减少了存储空间的占用,但查询效率相比 md-hbase 提升不显著。r-hbase[20]从多维索引结构和空间填充曲线两个方面对md-hbase作出了改进,用r树替换掉了不支持范围查询的k-d树,并提供了hilbert曲线和z曲线两种底层编码方式。然而,r-hbase并没有解决 md-hbase 无法支持数据并发写入的问题,仍需要进一步改进。hcindex[21]提出了一种包括关系表、坐标表和存储表的三元组索引结构,为字符串类型的数据提供了索引支持。然而,hcindex占用较多的存储空间,且无法支持动态的插入和更新数据。geomesa[22]使用z、xz-ordering等空间填充曲线多维空间数据,以支持hbase的数据插入和查询。然而,geomesa仅针对地理时空数据给出了九游会j9登录的解决方案,然而对于其他多维数据并不具备通用性。