基于python爬虫的新浪财经股票的文本挖掘处理系统设计与实现 毕业论文 答辩ppt 项目源码-九游会j9登录
以浏览器-屏幕为媒介传播的财经网站所披露的新闻,涉及到了上市公司的董事意见、产业行情、经营水平和财务战略决策等一系列重要信息,是股民进行投资的重要信息来源。因此大型财经新闻网站的报道,将在一定程度上影响股民的判断与决策。但是,财经新闻的价值到底有多大,如何以批判性思维的角度来辨识财经新闻,是各国学者进行财经研究与分析的热点。
文本挖掘是数据挖掘技术的一个重要组成部分,它通过计算机自动地从不同的文本源中抽取出可用的信息。把这种信息与新现象和假设联系起来,以探索出传统研究手段所研究不到的盲点,是文本挖掘的要点与难点所在。因此,面向财经新闻,构建文本挖掘系统,指导股民进行投资决策,具有理论价值也应用价值。本文通过系统设计与分析后发现,新闻报道中积极词汇往往多于消极词汇,而且新闻报道的情感与股市的涨跌没有正相关关系。此外,本文使用了arima模型,基于板块数据对未来7天的相关板块趋势进行预测,具有一定借鉴指导意义。
关键词:文本挖掘;财经新闻;投资决策;arima模型
the news, which propagated by the media of browser – screen, involves the directors of listed companies of opinion, industry, market, management level and the financial strategy and so on, is important information source of investors to invest. thus, the reported by the large financial news website will to a certain extent affect people’s judgment and decision-making. how much the value of the financial news, and how to identify the perspective of critical thinking in the financial news, is a hotspot of financial research among international scholars.
text mining is an important part of data mining technology, which can automatically extract from different text source of the information available through the computer. it is the point of text mining and the difficulty, to relate this information with the new phenomenon and assumptions, and to explore the blind spot of traditional research methods research is less than. therefore, it has the theory value and application value, to construct a system of text mining, guide people to investment decision-making, facing the financial news. in this paper, through the system design and analysis, found that after active vocabulary is often more than the negative words in the news report, and news reports of emotion and downs of the stock market is not positive correlation. in addition, this paper use the arima model, based on the plate data to forecast the future trend of the seven days of related sectors, has certain guiding significance for reference.
keywords:text mining;financial news;investment decision;arima model
目录
摘 要
abstract
1.绪论
1.1 研究目的和意义
1.2 财经新闻综述
1.3 关于python爬虫
1.4 文本挖掘概述
1.5本系统架构
2. 数据榨取与分析
2.1 网页源代码分析
2.2 数据清洗与过滤并规则化
2.3 中文分词
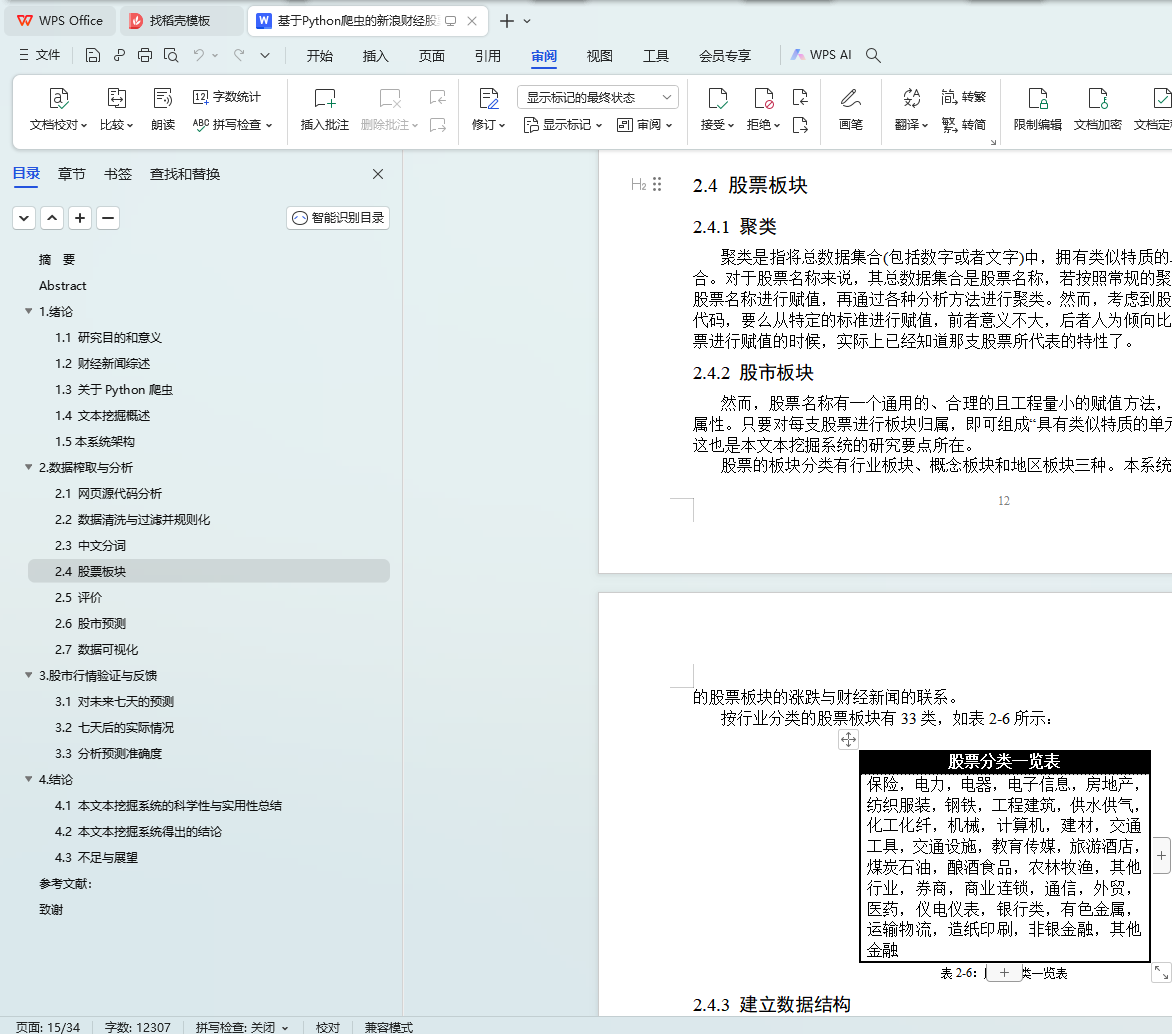
2.4 股票板块
2.5 评价
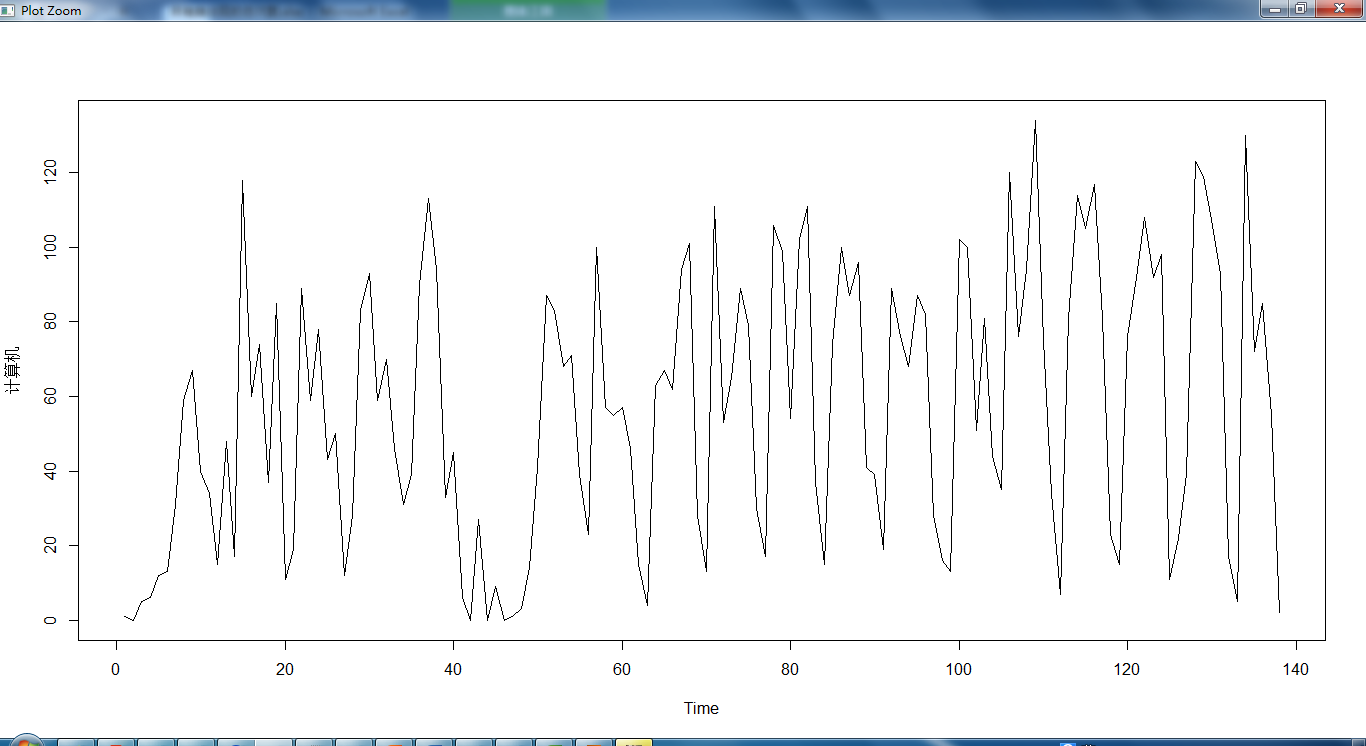
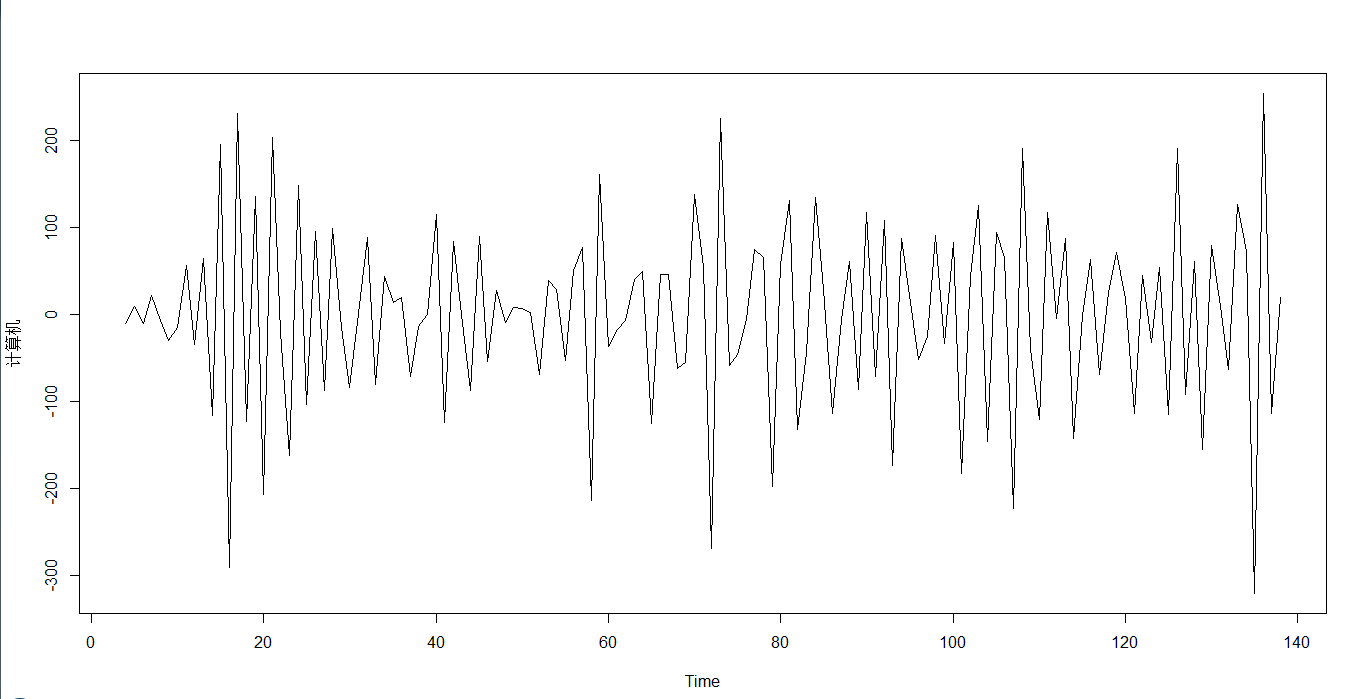
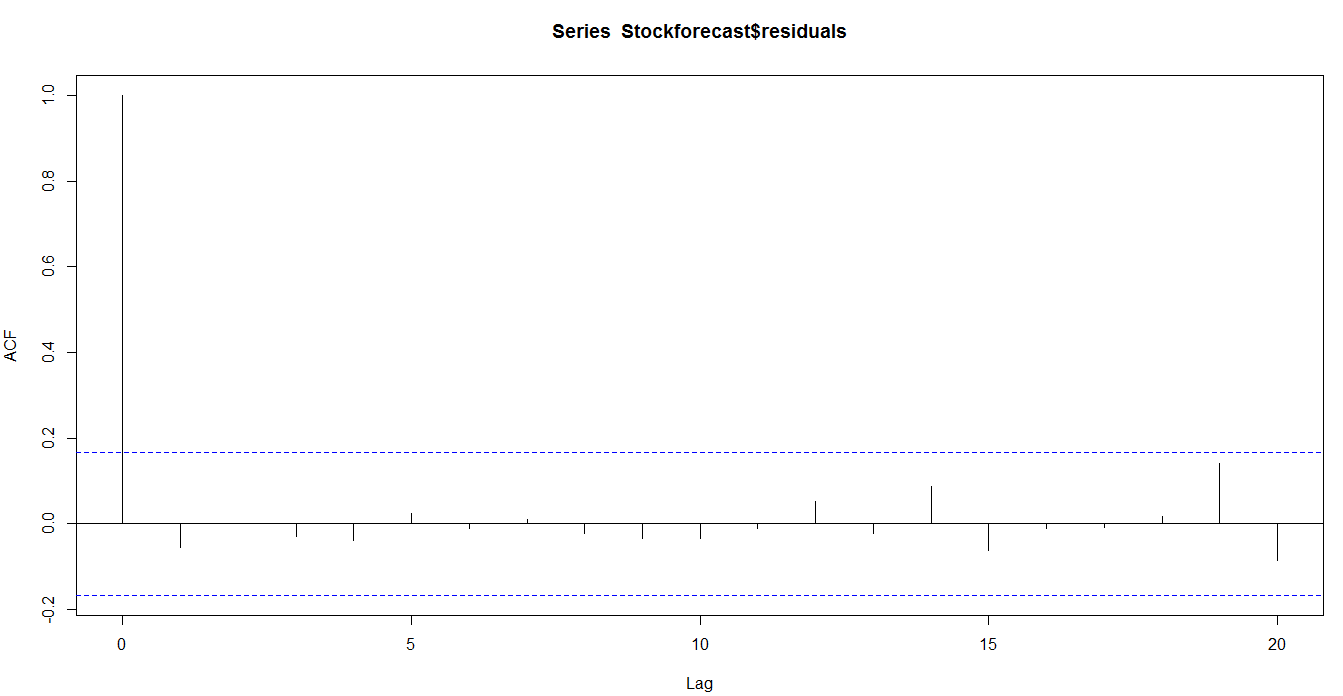
2.6 股市预测
2.7 数据可视化
3. 股市行情验证与反馈
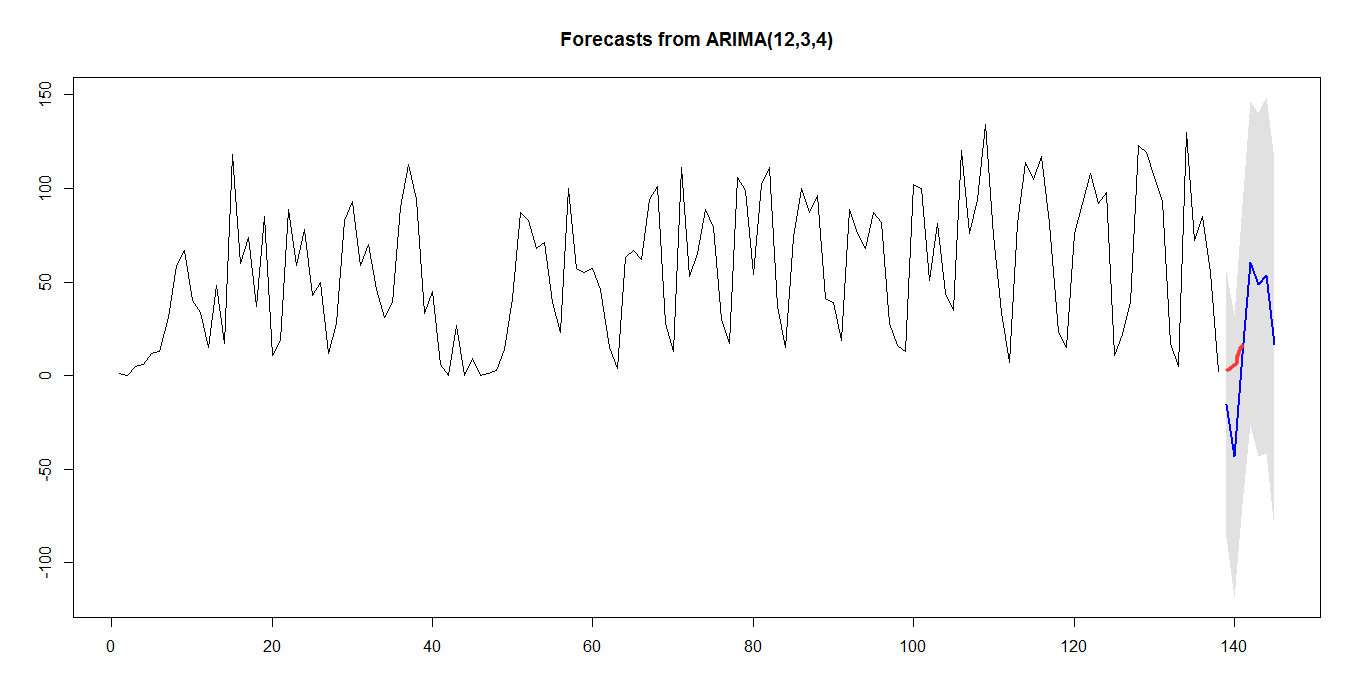
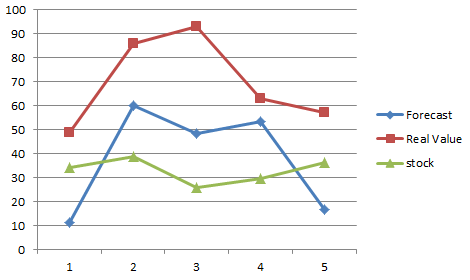
3.1 对未来七天的预测
3.2 七天后的实际情况
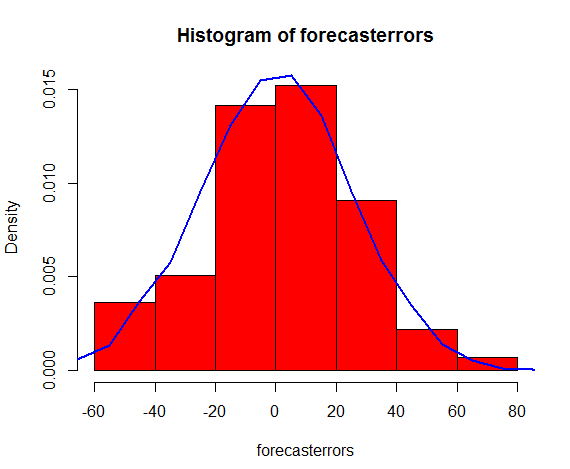
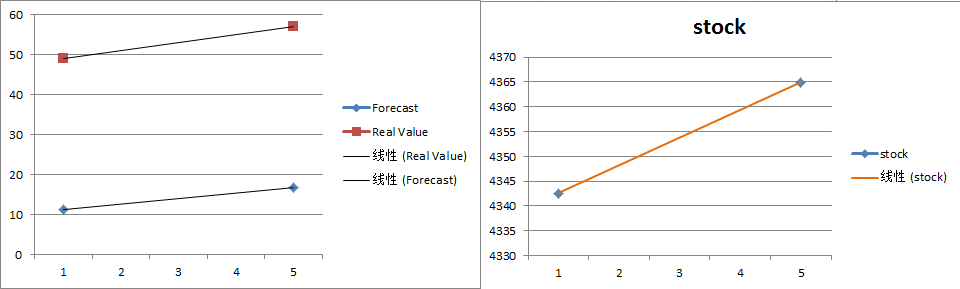
3.3 分析预测准确度
4. 结论
4.1 本文本挖掘系统的科学性与实用性总结
4.2 本文本挖掘系统得出的结论
4.3 不足与展望
参考文献:
致谢